Microservice communication: Orchestration vs. choreography
TLDR: The practical choice between orchestration and choreography
Choreography scales autonomy by letting services react to events without a central controller, while orchestration centralizes control to make workflows explicit and easier to govern. The “right” approach depends on reliability needs, debugging tolerance, and compliance constraints—especially for notifications. This is where build vs buy becomes real, not theoretical.
Why this debate matters more than architecture purity
Orchestration vs choreography isn’t just a design preference—it shapes your operational complexity, failure recovery, and how quickly you can scale critical workflows like customer notifications. When infrastructure must handle millions of messages and evolving compliance (GDPR/ISO), communication patterns stop being “internal plumbing” and start becoming a business constraint.
Every engineering leader has faced the classic build vs buy dilemma. For critical infrastructure like notification systems, the decision gets harder: building gives control, buying accelerates time-to-value. And the tradeoffs become sharper once your microservices need reliable, scalable communication.
To put this into perspective: building a notification system capable of handling millions of messages per day might require a team of engineers, months of development time, and ongoing compliance updates for regulations like GDPR or ISO. Buying middleware can reduce implementation time by 70–80%, freeing resources for product innovation.
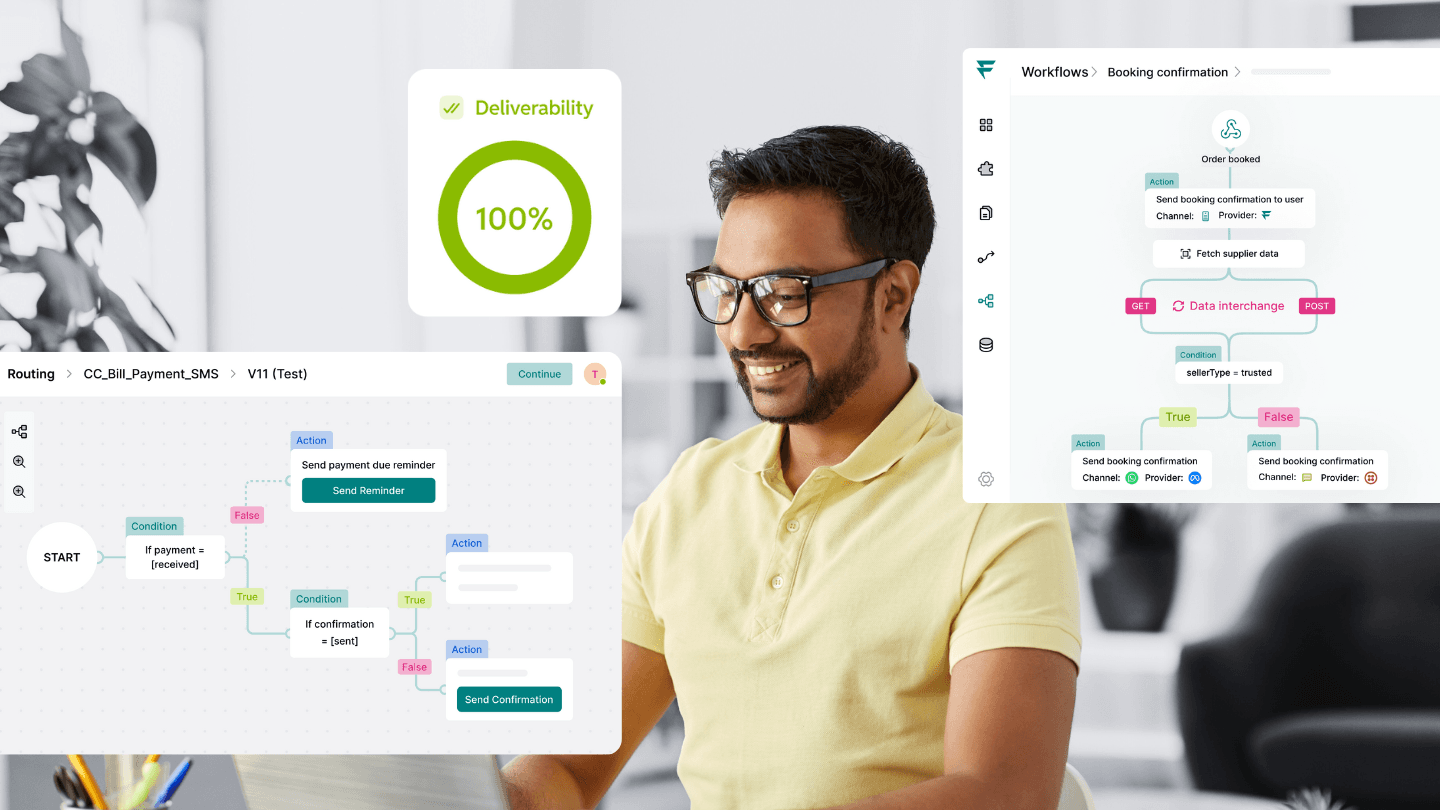
Choreography in microservices: A deeper dive
In microservice architectures, choreography employs a decentralized, event-driven approach where services communicate through asynchronous messages rather than relying on a central orchestrator.
Core principles of choreography
Event-driven design: Services broadcast events when state changes occur, enabling other services to react autonomously. For instance, a payment service might emit a "Payment Processed" event, triggering downstream services such as inventory updates or notification dispatch.
Asynchronous messaging: By relying on message brokers like Kafka, RabbitMQ, or AWS SQS, services achieve loose coupling and non-blocking communication. This ensures high availability and responsiveness even under heavy load.
Microservice communication challenges
1. Systemic complexities
Microservices thrive on independence but struggle with coordination. Latency issues emerge when services must wait for data or responses, leading to cascading slowdowns across the system. For example, in a payment gateway handling high transaction volumes, even a 200ms latency in validating a transaction can create bottlenecks, disrupting the user experience.
Consistency is another hurdle. How do you ensure that customer data is identical across microservices when one service fails? Techniques like event sourcing and distributed transactions can help but often come with trade-offs in complexity and performance.
Failure recovery, too, is intricate. A failing service might impact downstream dependencies unless a circuit breaker pattern is implemented.
2. The scalability imperative
Scaling microservices isn’t just about adding more instances. As service dependencies multiply, communication between them must scale efficiently.
Consider a logistics company: as new regional hubs integrate into its system, the load on APIs spikes. Without asynchronous messaging or service meshes like Istio, latency and communication costs balloon. Furthermore, synchronous communication, such as direct API calls, can become a bottleneck during peak load.
As Martin Fowler emphasizes, "Integration points are where systems are most likely to break," making scalable communication an imperative for engineering leaders.
3. Strategic framing
Why does this matter? Unaddressed communication challenges can cripple growth. Imagine a bank’s microservices failing to reconcile transactions in real-time during a holiday sale, a situation that could lead to financial losses and erode customer trust.
Solving these challenges isn't just about technical fixes; it's about aligning architecture with business objectives. Engineering leaders must invest in proactive monitoring tools, well-documented APIs, and disaster recovery strategies to ensure systems remain resilient under load.
Other issues like debugging distributed systems is notoriously difficult. A single event may trigger multiple services, making it challenging to trace issues. Maintaining compatibility during schema changes is critical. Breaking changes can disrupt downstream consumers.
Orchestration
In a microservices architecture, orchestration centralizes the control of service interactions through a designated orchestrator. This orchestrator coordinates the sequence and execution of tasks, ensuring that services work in harmony to achieve a specific business objective.
Tools such as Kubernetes, Apache Airflow, and Camunda are widely used in the industry, providing automated workflows, scaling, and monitoring.
Core principles
Orchestration operates on the premise of centralized governance, where the orchestrator directs every step of the process. It ensures:
Explicit workflow control: The orchestrator defines and manages workflows, ensuring all components interact predictably.
Error handling and retries: Centralized systems can identify failed steps and reattempt them without disrupting the entire workflow.
Scalability through automation: Allows automated scaling of services based on real-time workload demands.
The real question: Build vs Buy?
Building your notification infrastructure in-house might seem appealing at first glance due to the promise of customization and control. However, the reality is more complex.
While you gain the ability to tailor solutions precisely to your needs, you also take on the heavy burden of operational costs, compliance efforts, and scalability challenges. Managing even a small team of engineers for this purpose can divert significant resources away from your core business objectives.
Building in-house: Pros and cons
Pros: Complete control over the infrastructure, allowing you to align it with specific organisational workflows.
Cons: Requires 1-2 full-time engineers, ongoing maintenance, and substantial effort to stay compliant with regulations like GDPR. Scaling during high-volume periods becomes a bottleneck without significant investment.
Buying a middleware: The game-changer
Platforms like Fyno offer out-of-the-box solutions that address these challenges. By eliminating the need for dedicated engineering efforts and offering plug-and-play integrations, Fyno enables organisations to scale quickly. It ensures 100% deliverability, seamless provider management, and compliance with key standards.
Decision factors: What should drive your choice?
Cost: Transitioning to a middleware can result in up to 80% savings in engineering overhead and other operational costs.
Expertise: Middlewares reduce the need for in-house expertise, letting your team focus on product development.
Scalability: Handle millions of notifications effortlessly with no-code drag and drop workflow builder.
Compliance: Built-in adherence to SOC 2, ISO, GDPR eliminates your compliance concerns.
Enter Fyno
Fyno is a modern communication stack to consolidate customer communications. It provides a powerful control centre orchestrate/ manage customer communications across any channel. Out feature set is extremely malleable and modular, allowing engineering and product teams to build and manage their use-cases with “limited to no coding” effort.
Intelligent routing: Configure cross-channel communication flows using a no-code interface, ensuring 100% deliverability with automated retries and failover protocols.
Multi-tenant workspaces: Manage distinct communication requirements by configuring unique integrations, workflows, and templates within separate workspaces, having a china-wall policy.
Template management: Create, edit, test, and publish multi-channel messaging templates in real-time without developer intervention, utilising a user-friendly drag-and-drop editor.
Powerful workflow engine: Design and automate communication pipelines with a drag-and-drop workflow builder, integrating seamlessly with various systems, analytics platform, or your backend.
Unified analytics: Access consolidated logs and real-time data across all channels and providers, enabling efficient troubleshooting and performance monitoring from a single dashboard.
So what should you do?
Well, when building your product, innovation and customer experience are your top priorities. But does your customer notification system receive the same attention?
At first, building your own notification infrastructure might seem like the right move. But as engineering resources and costs pile up, what starts as a simple ‘in-house solution’ quickly turns into a bottleneck, diverting focus from the areas that actually drive revenue.
Before you take a call, ask yourself these questions.
How does your current notification infrastructure handle unexpected spikes in volume?
What’s the operational cost breakdown of maintaining your in-house notification system?
How quickly can you integrate new communication channels or features into your current system?
How much time and effort does your team spend ensuring compliances like GDPR?
Does maintaining your notification system take your team’s focus away from your core product?
Are you compromising on deliverability or costs just because it is painful to integrate a new vendor?
What’s your deliverability rate across all notification channels?
Are your customers paying you to receive these communications or your core offering?
Are you able to observe your providers’ performance and communication insights?
If these questions left you unconvinced that your current setup is efficient, scalable, and cost-effective, then it’s time to rethink your approach.
Now, if you could free up 70% of your operational costs for notifications, how would you reinvest those savings? Talk to us today to see how you can get started and transform your customer notification strategy.
Conclusion
Choreography and orchestration aren’t competing ideologies—they’re tools for managing coordination in distributed systems. As microservices scale, communication becomes a business risk surface: latency, consistency, failure recovery, and compliance all compound. That’s why the build vs buy decision for notification infrastructure matters—and why middleware exists to absorb the complexity you don’t want to own.
Comments
Your comment has been submitted